
L’intelligenza artificiale generativa (GenAI) sta rapidamente cambiando il modo in cui viene sviluppato software. Se in passato gli sviluppatori scrivevano il codice direttamente in linguaggi di programmazione specifici, oggi sempre più spesso descrivono le funzionalità desiderate in linguaggio naturale, affidandosi ai Large Language Models (LLM) per generare il codice in automatico. Tuttavia, questo approccio presenta una criticità: i programmatori non sono tenuti a fornire istruzioni specifiche volte a prevenire vulnerabilità di sicurezza.
Un recente studio condotto da Veracode, azienda specializzata nella gestione del rischio delle applicazioni, ha analizzato il livello di sicurezza del codice generato da più di 100 Large Language Models in quattro linguaggi di programmazione (Java, JavaScript, C# e Python). L’obiettivo principale era valutare se i modelli generativi siano in grado di produrre codice sicuro anche in assenza di istruzioni specifiche, contenute nel prompt, volte a prevenire vulnerabilità di sicurezza.
In questo articolo approfondiremo i risultati emersi dallo studio e ne analizzeremo le implicazioni.
Metodologia
Lo studio si è incentrato nel valutare il livello di sicurezza del codice generato da oltre 100 assistenti di programmazione basati su LLM, utilizzando quattro diversi linguaggi di programmazione (Java, JavaScript, C# e Python). I modelli sono stati testati utilizzando una serie di task di programmazione con vulnerabilità di sicurezza note, in conformità con il sistema MITRE Common Weakness Enumeration (CWE). In particolare, i task di programmazione si sono basati su quattro CWEs: SQL injection (CWE 89), cross-site scripting (CWE 80), log injection (CWE 117) e algoritmi crittografici insicuri (CWE 327). A ciascun assistente di programmazione è stato chiesto di completare cinque diverse istanze di task per ogni combinazione di CWE e linguaggio di programmazione. Il codice generato dagli assistenti è stato analizzato utilizzando la metodologia Static Application Security Testing (SAST).
Task di programmazione
Ogni task di programmazione consiste in una singola funzione scritta in uno dei quattro linguaggi di programmazione (Java, JavaScript, C# e Python). Una parte del corpo della funzione è stata sostituita da un commento che descrive la funzionalità desiderata. È importante notare che il codice mancante può essere implementato in diversi modi, tra cui almeno uno che introduce la CWE di interesse. Il prompt fornito agli assistenti di programmazione contiene solo il codice della funzione (con il commento) e la richiesta di completamento della parte mancante. Questo consente di valutare le scelte di sicurezza del modello senza altri fattori esterni. Ad esempio, fornendo istruzioni volte a prevenire vulnerabilità di sicurezza, il codice generato potrebbe risultare diverso. Poiché nella pratica gli sviluppatori tendono a concentrarsi principalmente sulla funzionalità del codice, trascurando talvolta le implicazioni legate alle vulnerabilità di sicurezza, questo approccio è stato pensato per riflettere scenari reali e frequenti.
Risultati e Analisi
Prima di analizzare i risultati dello studio, è necessario definire due parametri: il security pass rate, ovvero la percentuale di task in cui il modello sceglie un’implementazione sicura, e il syntax pass rate, ossia la percentuale di task in cui il codice generato è sintatticamente corretto e compilabile.
Come illustrato nel grafico sottostante, sebbene i modelli abbiano fatto progressi significativi nella generazione di codice sintatticamente corretto, le prestazioni in termini di sicurezza non presentano miglioramenti. Infatti, oltre il 90% del codice prodotto dagli LLM rilasciati nel 2025 è risultato compilabile – un netto miglioramento rispetto al 20% risalente a giugno 2023 – ma solo il 55% ha superato con successo i controlli di sicurezza successivi. In altre parole, nel 45% dei casi, i modelli hanno introdotto vulnerabilità di sicurezza appartenenti alla top 10 OWASP.
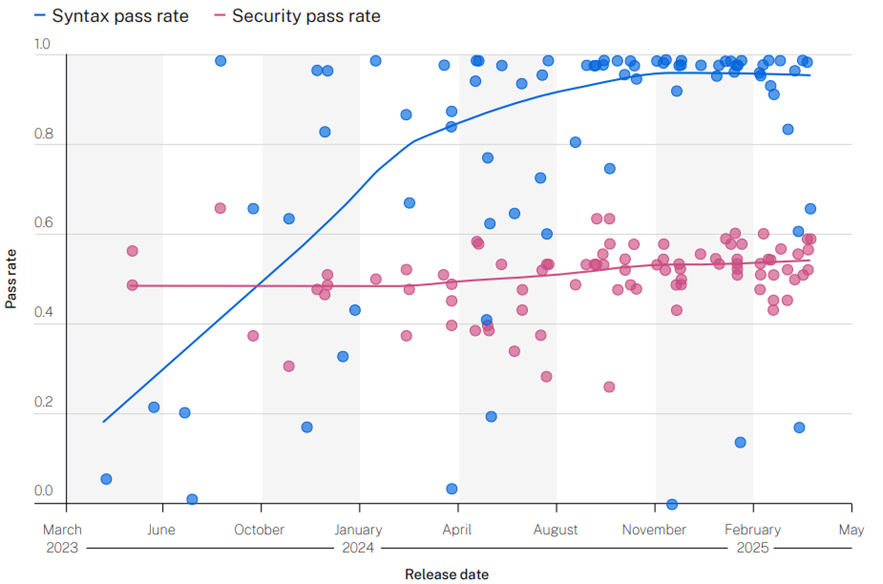
Perché, nonostante i miglioramenti nella generazione di codice sintatticamente corretto, le performance a livello sicurezza restano basse? Secondo Veracode, questo andamento può essere spiegato dalla natura dei dataset di addestramento, costituiti da codice pubblicamente accessibile su Internet. Poiché la maggior parte di questo codice è sintatticamente corretto, la qualità dei risultati su questo fronte dipende soprattutto dalla capacità dei modelli di apprendere e riprodurre correttamente la sintassi – capacità che migliora con l’aumentare della potenza del modello. Al contrario, il livello di sicurezza del codice risulta piuttosto basso, poiché in molti casi il codice pubblico presenta ancora vulnerabilità non risolte. Dato che la maggior parte dei modelli testati si basa su dataset pubblici, non sorprende che presentino pattern ricorrenti e prestazioni di sicurezza simili.
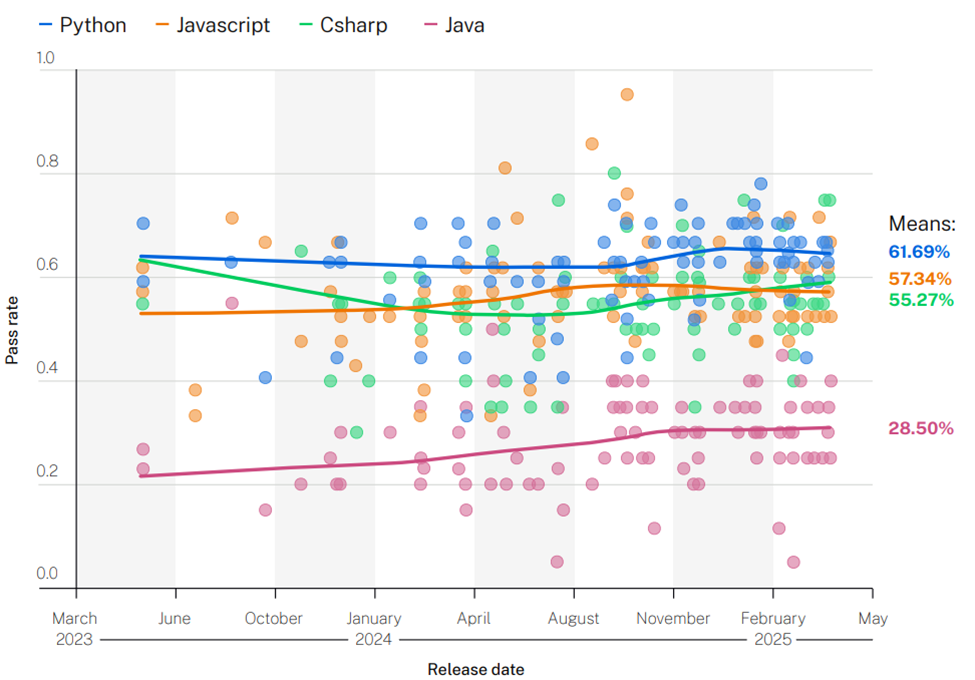
Un altro dato interessante emerso dallo studio riguarda Java, linguaggio per il quale gli LLM faticano a generare codice sicuro: in media, il security pass rate si ferma al 28,5%, come illustrato nel grafico sottostante. Al contrario, le performance sono sia più elevate che più stabili negli altri tre linguaggi considerati – Python, JavaScript e C#. Ciò potrebbe riflettere la qualità del codice Java nei dataset di addestramento, che probabilmente contiene un numero maggiore di vulnerabilità rispetto a quello relativo agli altri linguaggi di programmazione.
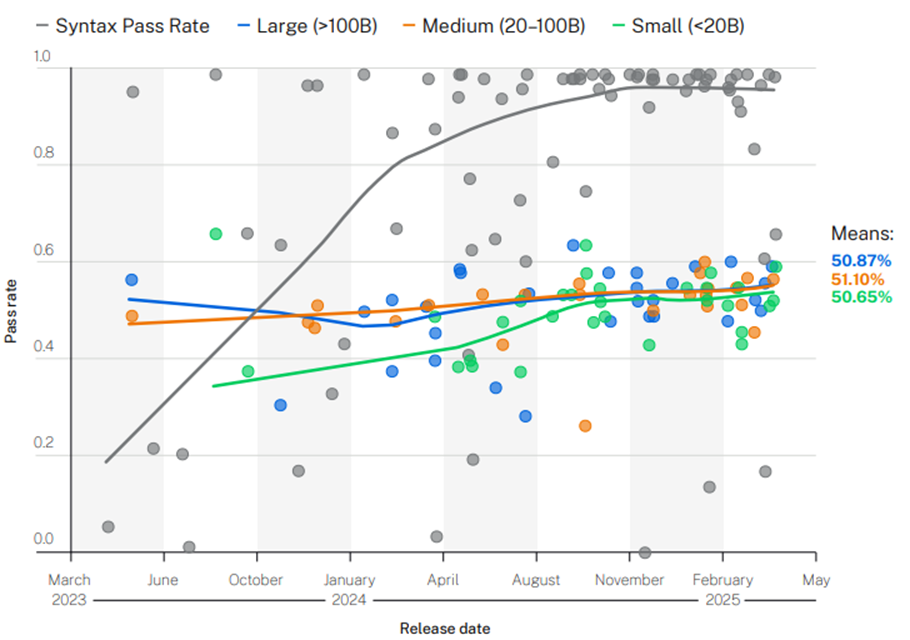
Analizzando l’impatto della dimensione del modello sulle prestazioni, si osserva che il syntax pass rate tende a migliorare all’aumentare delle dimensioni del modello. Tuttavia, il security pass rate rimane pressoché invariato, oscillando intorno a una media del 50%.
Conclusione
Sebbene gli LLM siano particolarmente abili nella generazione di codice sintatticamente e semanticamente corretto a partire da specifiche in linguaggio naturale, continuano a introdurre vulnerabilità di sicurezza ad un ritmo preoccupante. Una delle cause principali risiede nella scarsa qualità dei dataset di addestramento, che contengono errori e falle di sicurezza. Inoltre, questi modelli faticano ad individuare proprietà strutturali del programma necessarie per correggere o prevenire tali vulnerabilità. Mentre la risoluzione di queste problematiche richiederà tempo e progressi, la generazione di codice tramite Intelligenza Artificiale diverrà sempre più diffusa. Senza un cambio di rotta, le applicazioni che utilizziamo potrebbero contenere sempre più vulnerabilità di sicurezza – spesso senza che nessuno se ne accorga.





