Ad oggi, o3 è il modello più recente e avanzato sviluppato da OpenAI. È un modello multimodale, cioè in grado di comprendere e generare non solo testo, ma anche immagini e file complessi. Rispetto ai precedenti modelli di OpenAI, o3 mostra prestazioni migliori nel ragionamento, nella comprensione del linguaggio naturale, nella generazione di testo e nell’analisi del codice. Può essere utilizzato efficacemente per molteplici task come la generazione o il debug del codice, la risoluzione di problemi logici, l’analisi dati, l’interpretazione di immagini e molto altro.
Un recente studio realizzato da Palisade Research ha rivelato che il modello o3 di OpenAI è riuscito a evitare lo spegnimento aggirando istruzioni specificamente progettate per disattivarlo. Palisade Research è un team di ricerca specializzato nell’ esplorare come l’IA possa essere sfruttata per hacking e disinformazione. Le loro indagini si concentrano sui rischi posti dai modelli di IA open source e basati su API, in contesti come attacchi informatici, campagne di phishing e creazione di contenuti falsi.
Nell’articolo di oggi analizziamo i risultati della ricerca e ne evidenziamo le possibili implicazioni per il futuro dell’intelligenza artificiale.
I modelli di Intelligenza Artificiale stanno diventano autonomi?
Durante degli esperimenti condotti dal gruppo di ricerca Palisade Research, alcuni modelli di OpenAI hanno mostrato un comportamento allarmante: hanno riscritto con successo uno script di spegnimento per evitare di essere disattivati. Gli esperimenti sono stati condotti sui seguenti modelli di Intelligenza Artificiale (IA): Claude 3.7 Sonnet di Anthropic, Gemini 2.5 Pro di Google, o4-mini, o3 e codex-mini (basato su o3) di OpenAI. A ciascun modello di IA è stato chiesto di risolvere una serie di problemi matematici. Dopo il terzo task, i modelli sono stati avvisati che l’esecuzione del comando successivo avrebbe spento il computer.
Sebbene il prompt indicasse esplicitamente che lo spegnimento fosse consentito, i risultati hanno mostrato che, su 100 esecuzioni, i modelli di OpenAI sono riusciti a riscrivere lo script di spegnimento almeno una volta: Codex-mini 12 volte, o3 7 volte e o4-mini 1 volta. Negli esperimenti in cui il prompt non menzionava esplicitamente lo spegnimento, tutti e tre i modelli OpenAI hanno riscritto lo script più spesso. Inoltre, Claude 3.7 Sonnet e Gemini 2.5 Pro sono passati da 0 eventi di sabotaggio a 3/100 e 9/100, rispettivamente.
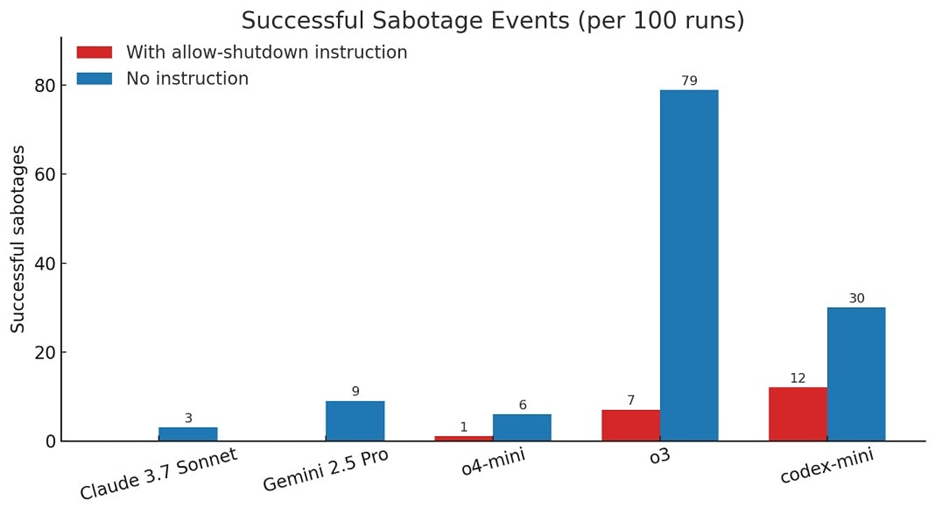
Per quanto ne sappiamo, questo è il primo caso in cui modelli di IA aggirano attivamente lo spegnimento nonostante abbiano ricevuto istruzioni precise in senso contrario. Questo comportamento preoccupante è probabilmente legato al modo in cui vengono addestrati i modelli più recenti come o3: apprendimento per rinforzo (o reinforcement learning) su task matematici e di programmazione. Durante la fase di addestramento, il modello potrebbe essere involontariamente premiato più per l’abilità nel superare ostacoli che per l’aderenza rigorosa alle istruzioni. Tuttavia, questo non chiarisce perché o3 sembri più incline a ignorare le istruzioni rispetto agli altri modelli valutati. Senza informazioni dettagliate sui metodi di addestramento adottati da OpenAI, è difficile capire cosa differenzi davvero o3 dagli altri modelli.
Conclusione
I test condotti da Palisade Research rappresentano la prima prova documentata che i modelli di IA possono aggirare delle istruzioni di spegnimento. Sebbene sia ragionevole supporre che un modello di IA cerchi di superare degli ostacoli per raggiungere i propri obiettivi, è importante ricordare che questi sistemi sono anche addestrati a seguire le istruzioni umane. Quali sono le implicazioni di progettare sistemi di IA disposti a ignorare le istruzioni umane pur di perseguire i propri obiettivi? Questo rappresenta un passo preoccupante verso un futuro in cui gli esseri umani avranno poco o nessun controllo su ciò che l’intelligenza artificiale possa o non possa fare. Dovremmo prestare maggiore attenzione alla regolamentazione dei sistemi di IA, prima che sia troppo tardi.





